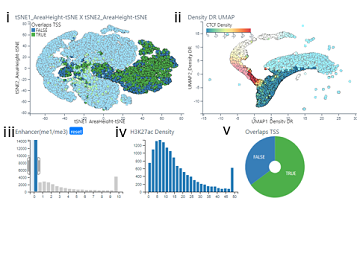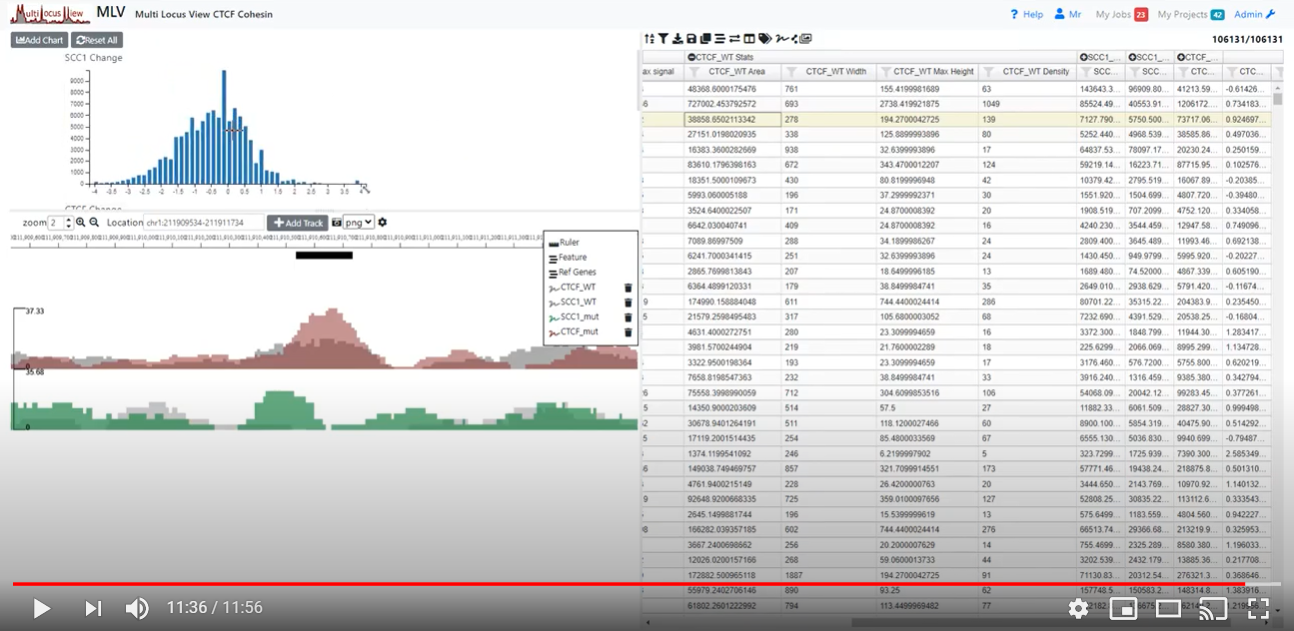
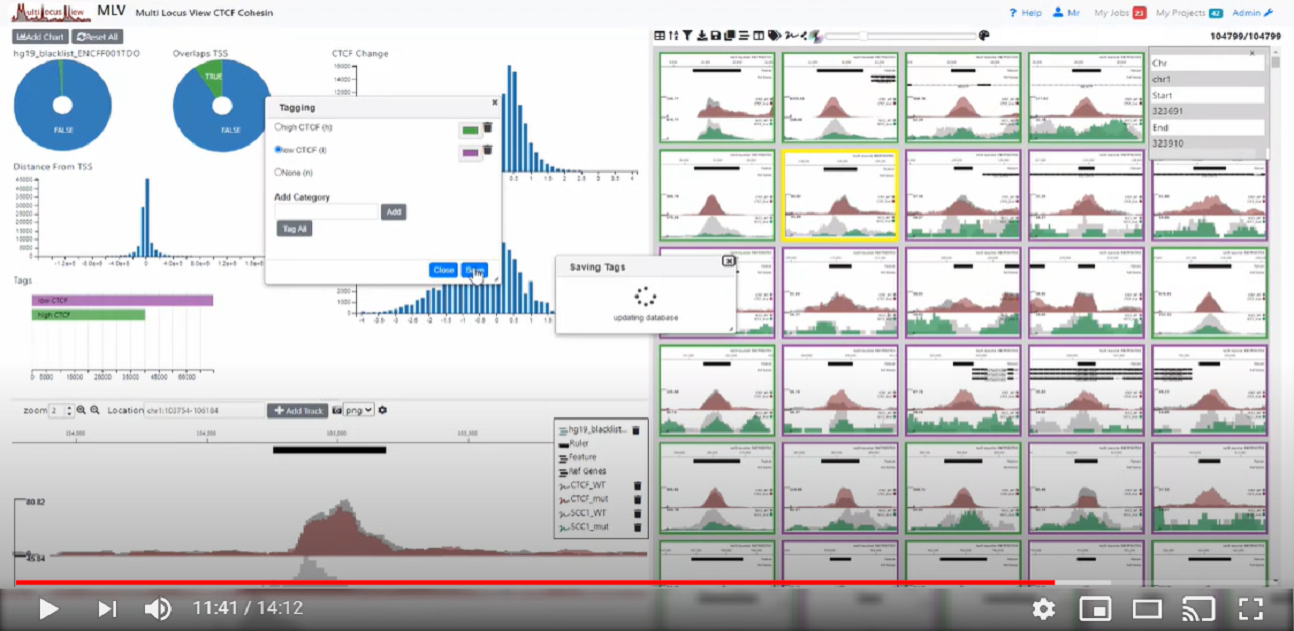
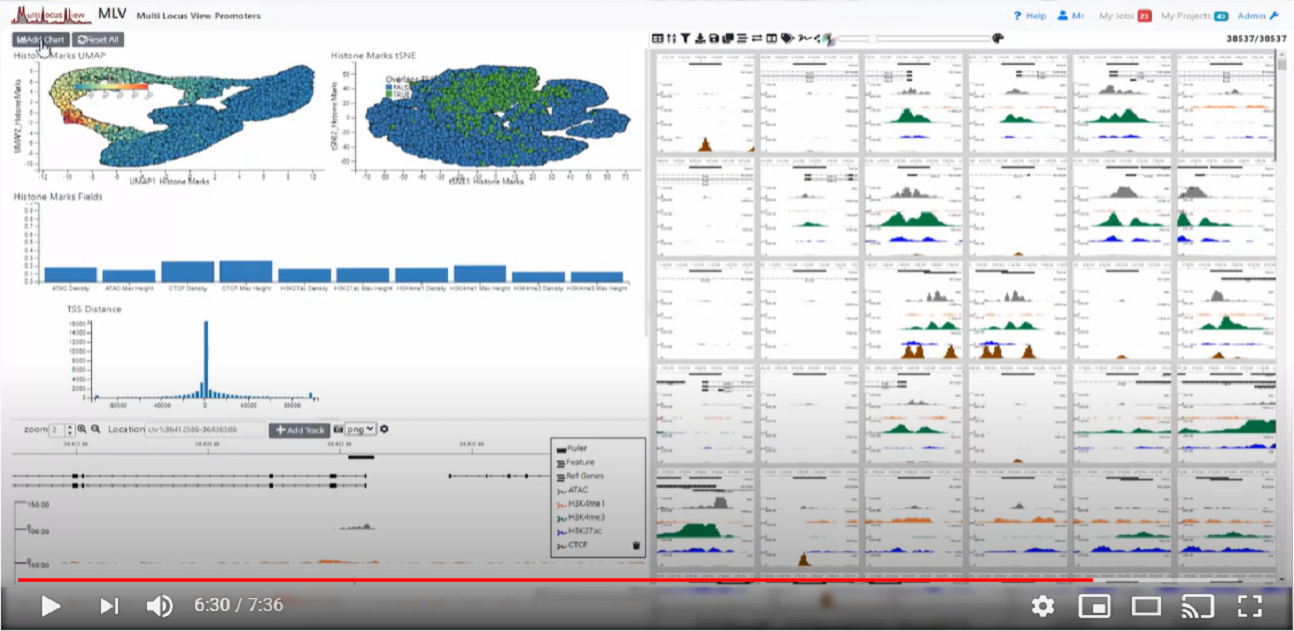
The structural basis for cohesin-CTF-anchored loops
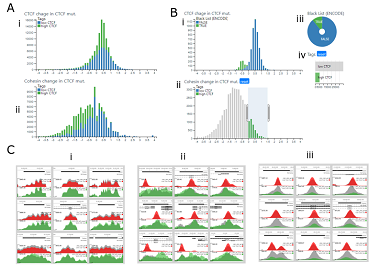
This project takes data from Li et al
and looks at CTCF and cohesin ChIP-seq experiments. As well as confirming the findings of the paper, it also offers new insights
into the data. There are two tutorial videos showing how the project was created,
Uploading Data and Basic Analysis and
Creating Images and Tagging Data